In this page I will go through the main concepts of Linux and will try to keep updating it. Fully understanding of the Linux concepts is essential for those that are working in Security, Big Data, HPC and DevOps areas.
Linux is an open-source Operating System (software) that locates between the software that is running on the system and the computer’s hardware. Similar to other OS, it transfers the request of programs to Hardware and vice versa. What distinct it from other OS is of being open source which has tremendous benefits to developers.
Let’s first understand the abstraction layers/levels that create Linux OS and then slowly move to other parts.
1. The Linux system has 3 main levels/layers
As can be seen in Figure 1 Linux has 3 main layers:
a. Hardware:
It is at the very bottom which includes RAM, CPU and other physical parts.
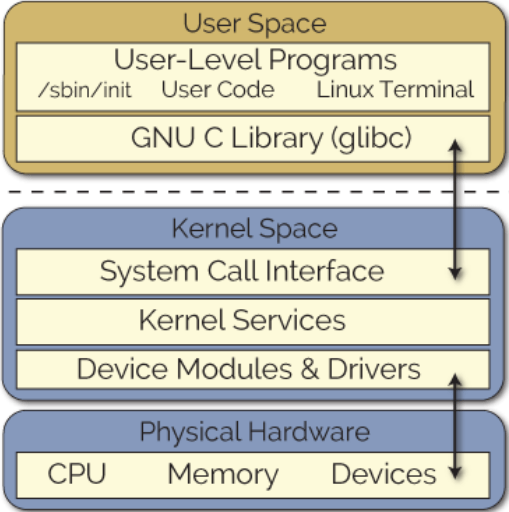
Figure 1: Linux abstraction Layers
b. Kernel:
At the top of the Hardware layer is Kernel. Kernel is a software which resides at the memory (RAM) and instruct CPU what to do. It’s a core part of Linux OS and act as a interface between Hardware and running programs.
As I can be seen in Figure 1, Kernel can be further divided into following 3 levels:
- System call interface: is the interface between an application and the Linux kernel.
- Kernel service (code): is the main kernel code which is architecture-independent
- Modules: It is a piece if code that can be easily loaded or unloaded on demand. It extends the functionality of the kernel. As an example, one type of modules are drivers that allows the kernel to communicate with the connected hardware. We can also see all actual kernel modules which has been loaded with “lsmod” command.
c. User Processes (programs):
It’s basically all programs that is running in Memory and being manged by kernel.
Description: to get an easier understanding of a process, it’s a bunch of bits (thousands of bits) that in that moment located at a specific area of the Memory. We can get the list of all processes running (located at memory in that moment of time) with:
rouhani@ubuntu ~ $ ps auxw
- ax: show all processes, not just what we own
- u: include more detailed info on processes
- w: show full command names (not just what fit)
Important: Obviously there are also some processes that runs in kernel level. The difference between the processes run in Kernel level and User Process Level is due to privileges that each have. The processes that runs in Kernel level has unrestricted access to entire Hardware. But in contrast, the User processes has restricted access to the memory and CPU. The terms is being used for them consecutively are Kernel Space and User Space. Keep it in mind that processes normally use system calls for communication with the kernel.
Let’s move to Linux file-system which I belive is one of the main and essential concept of Linux OS.
2. Linux Directory structure
The best to start is to explore the file-system. Figure 2 shows the simple Linux file-system structure with a bit explanation.
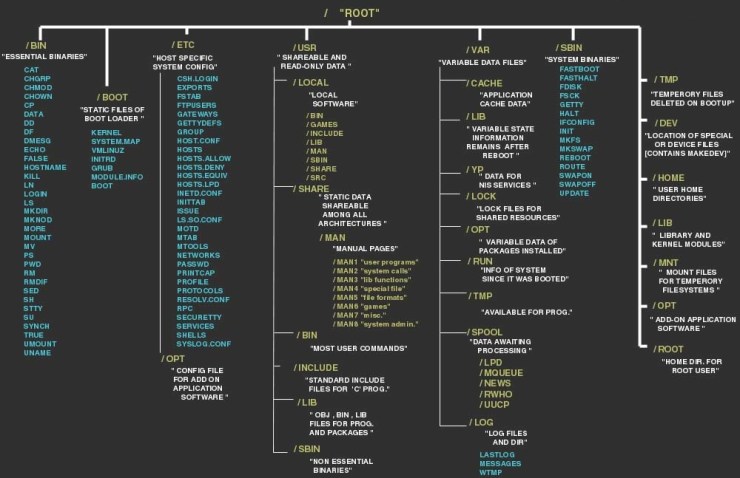
Figure 2: Linux Directory structure
I will go through some of the most important directories here:
/bin: contains the executable (binary format) programs that are essential to have a minimal functionality of the system like booting and repairing purposes. There is a difference with /usr/bin which contains programs that are not made for booting or repairing purposes.
/boot: it contains kernel boot loader files which being used only at the very first stage of the Linux startup.
/etc: this is the core system configuration directory which contains all system related configuration files. Keep it in mind that configuration files cannot be an executable binary. Some examples are:
- /etc/passwd
- /etc/fstab
- /etc/motd
- /etc/shells
/opt: this directory is reserved for all software/packages that are not part of the default installation. It is quite similar to /usr/local and not easy to define a explicit differences these days.
/usr: most of the user-space programs and data located here. It contains several sub-directories such as:
- local: is where admin can install their own software.
- Include : header files used by C compiler
/lib: includes library files that executable codes can use. There are 2 types of libraries – Static & Shared – which here we have only shared libraries.
/sbin: includes programs (binary format) for System management, so usually it runs only as root.
/var: programs record runtime information here. System logging, user tracking, caches and other files that system programs create and manage are here.
/dev: device files
we can use sever method to find out the devices such as:
- using “udevadm” command.
- cat /proc/devices
- Check the /dev directory for Block devices (start with b in file attributes like brw-rw—-)
- to list all device on the system (scsi), you can use “lsscsi” command rouhani@cassius ~ $ lsscsi [0:0:0:0] disk ATA ST3250318AS CC49 /dev/sda[1:0:0:0] disk ATA ST31000528AS CC49 /dev/sdb[2:0:0:0] cd/dvd TSSTcorp DVD+-RW TS-H653H D700 /dev/sr0
3. Users
Another important concept is Linux is Users. The user is an entity that can run Processes, own files and have a full control over their processes and files. However we have a username for each user, but kernel manages users by an “id” called UID. There is a user called “root” which is an exception since has a control over all processes (even other user’s processes) and can read any files.
4. Shell
It is a program that is responsible for running the commands that user enter. There are several different shells in Linux (such as bash, csh, ksh…), but the default and most famous one in Bourne Shell which is also called “bash” shell and usually /bin/sh has a softlink to bash:
rouhani@ubuntu ~ $ ll /bin/sh
lrwxrwxrwx 1 root root 4 Dec 9 2014 /bin/sh -> bash*
In general Shell needs some special settings to determine its behavior when interacting with our server/system. There are several ways of doing it which the most important ones are:
- shell variables
- Environment
The shell can store some values for different variables in case of needs which is called “shell variables”. However it is temporary and will be gone by closing the shell terminal. Assigning the values is very easy and can be done by using “=”:
- rouhani@ubuntu ~ $ country=DE
- rouhani@ubuntu ~ $ echo $DE
- DE
Due to importance, i will go through environment with more details in next section.
5. Environment
It is an area containing variables/settings that will be created by shell every time it starts a session in order to define system properties. All variables in environment can be accessed in the commands that shell runs basically for any processes (programs) or child shells, and this is one of the main difference with shell variables that is only accessible to the shell itself and not any other processes.
To make it very simple to understand, I can say “environment variable” is simply a variable with name and value, similar to shell variables but with some advantages as mentioned above. Let’s have some examples of enviromental values:
- default editor that should be used
- location of executable programs in the system
We can see the list of environmental variables by using “env” or “printenv” commands.
There are 2 ways of setting environment variables:
a. Temporary
These variables are not specified in any configuration files and being set by using a special set of commands like “export”. These environment variables last only until the current session. As an example, lets configure proxy for our current session:
- export http_proxy=http://xxx.hrouhani.org:2552/
- export https_proxy=http://xxx.hrouhani.org:25552/
b. Permanent
Here we need to put our commands in some files to make it permanent. But it is indeed make difference in which files to write our commands. Therefore we have 2 types of configuration files which are System-wide and User-wide configuration files:
b.1 System-wide configuration files: These files are loaded every time system is coming up and variables are loaded for any user logged in. The list of files are:
- /etc/bashrc(or /etc/bash.bashrc in some distributions)
- /etc/profile
- /etc/profile.d/*.sh: in some distribution like Redhat, if the users shell is a interactive shell, the /etc/bashrc also execute the shell scripts within /etc/profile.d/
b.2 User-wide configuration files: these files get loaded every time a user logged in and open a terminal. The list of files are:
- .bashrc : located at user home directory. For root is located in root home dir which is /root/.bashrc
- .profile
- .bash_profile
Description: To make it easier to remember:
- /etc/profile is the system wide version of .bash_profile
- /etc/bashrc is the system wide version of .bashrc
Example: One of the important environmental variable is “PATH” which contains system directories that the shell searchers when trying to locate a command.
rouhani@cassius ~ $ echo $PATH
/home/rouhani/bin/amd64-linux/suse131:/home/rouhani/bin/amd64-linux:/home/rouhani/bin:/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/kde/bin:/opt/gnome/bin:/usr/lib/java/bin:
We can also change this PATH by adding more dir in the beginning or end of this path. We have to keep it in mind that the orders matter. (here we change temporary)
- PATH=dir:$PATH beginning of the path
- PATH=$PATH:dir end of the path
6. Permissions
Every file in Linux has a set of permissions that determine whether we can read, write or run the file.
- rouhani@ubuntu ~ $ ls -la
- drwxr-xr-x 2 rouhani hrz 4096 Aug 21 15:01 Ariana/
- -rw-r–r– 1 rouhani hrz 12359680 Jul 7 08:39 Backup.tar
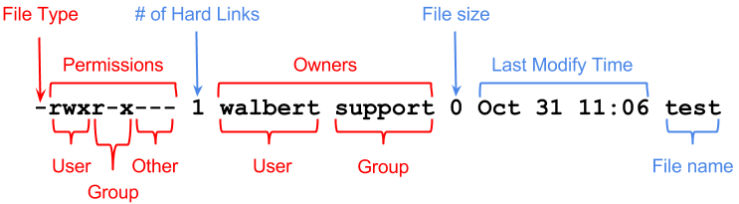
File type: can be “-” which means regular file or “d” which means a directory.
- User: It is related to the user who owns the file and can take advantage of those permission.
- Group: Any user in that group can take advantage of those permissions.
- Other: Anybody else
To change the permissions is very easy. We can use “chmod” command to do this in 2 different ways:
a. by specifying
chmod u+rwx : means give user the read, write and execute permissions
chmod g+r : means give group the read permissions
b. By numbers: it is much easier and we can set the permission for several in one command. It is easier to memorize following principle:
- 1: execute
- 4: read
- 5: read/execute
- 6: read/write
- 7: read/write/execute
So we can create a combination of above numbers and change permissions such as :
- 600: user(rw) and group/others none
- 644: user(rw) and group/others read
- 700: user(rwx) and group/others none
- 755: user(rwx) and group/others rx
- 777: all have rwx
so for example: chmod 755 file
7. Display Modes and Virtual Console
comes soon …
8. Linux Kernel boots
Kernel boots (starts) means moving the kernel into the memory and starting first user process. I will summarize the boot process into following 6 steps as can be seen in Figure 3:
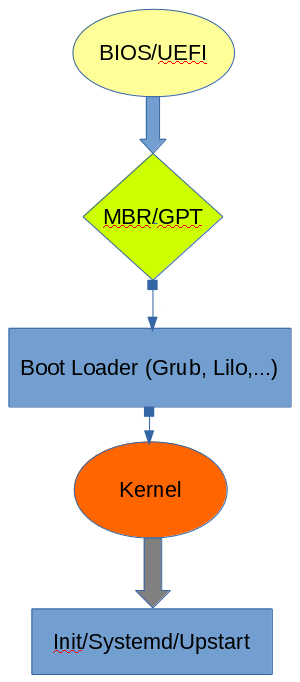
Figure 3: Linux Boot process
a. BIOS/UEFI
Either of the Bios or Uefi (which are low level software that starts when we boot the system) performs some system integrity checks and eventually search (might be in USB, Cd-Rom or Disk…) and loads the “boot loader” program (stored in partition table scheme such as MBR/GPT) into memory and gives the control to it.
Description: almost all new systems use UEFI firmware instead of traditional BIOS. There are many new features in UEFI such as:
- can boot from drivers of 2.2 TB or larger (coy use GPT)
- faster boot times
- More security features
Description: boot loader is the first computer program that runs when a system starts and is responsible for loading & transferring control to the OS kernel software. There are many of them, but I would say one the most famous one is GRUB.
b. MBR/GPT
As I mentioned before, the boot loader program is stored in the partition table which can have 2 different layout/schema – MBR or GPT. Either of the mentioned layout being used will load and execute the boot loader.
Description
MBR: It is the information in the first 512 bytes of a storage device which is responsible to identifies how and where an OS is located that it can be loaded into the RAM. It contains an OS bootloader (master boot code) and the storage device’s partition table.
GPT: It is a new layout of the partition table which has several advantage over MBR. It has been designed mainly for UEFI but also can be used for BIOS. One of the main advantages of the GPT over MBR, is that GPT does not have disk limitation of up to 2TB in size.
c. Boot Loader
The job of the boot loader is to find the kernel (on disk, network, USB,…), loads it into memory and starts it by passing a set of parameters.
There are many different boat loader in Linux which following 4 are most famous:
- Grub
- LILO
- Burg
- Syslinux
I would say Grub is the most popular boot loader available. One of the most important Grub capabilities is file-system navigation that make it easier to choose kernel image and configuration. We can see Grub menu easily at first when BIOS/UEFI start the system as can be seen here:
Above is the Grub menu in boot up, however there is also a Grub configuration file inside OS which in the new Grub version is called grub.cfg. There are 2 important line in grub configuration file which is Kernel and initrd locations. As an example:
kernel /boot/vmlinuz-2.6.18-194.el5PAE ro root=LABEL=/
initrd /boot/initrd-2.6.18-194.el5PAE.img
In spite of the fact that Grub is being installed during OS installation, we can also install it manually.
BIOS: grub-install
--boot-directory=/boot/grub
/dev/sda
UEFI:
grub-install –efi-directory=efi_dir
–bootloader-id=name
Description
initrd (initial Ram disk) is used by kernel as temporary file-system (initial root file-system) until kernel is booted and the read root file-system is mounted.
Description
There is a new version of Grub which is called Grub 2. There are some changes or improvemnet with Grub 2 which are:
- the conf file has new name which is grub.cfg (instead of grub.conf)
- grub.cfg is usually generated by grub-mkconfig (shell script) that runs everything in /etc/grub.dgeub-mkconfig -o /boot/grub/grub.cfg
- it is available not only for Bios system but many others such as EFI,PowerPC,…
- many other file-system is supported such as ext4, ntfs,…
- it can read files directly from LVM and Raid devices
d. Kernel
So now that kernel has been loaded, it will do following steps:
- mounts the root file-system (first the temporary root file-system by using initrd and then the real one)
- initializes the devices and its drivers
- start the first program called init/systemd/upstart (/sbin/init or /usr/lib/systemd/systemd or ) – stand for initialization- which get the PID=1. At some point init also start a process which let us to login (so User Space start)
e. initializaion process (Init/systemd/upstart/…)
Kernel will start an initialization process which can be any of the init, systemd, upstart and etc which is the first “user space” process (it will be the parent of all other processes), and it will start/builds up the rest of the system which usually end with Login prompt, GUIs and other high level applications. So simply I would say, the main purpose of the initialization process is to start and stop essential services on the system. However the new versions like systemd or upstart have more features and responsibilities.
There are 3 main implementation of the initialization process in different Linux distribution:
1. SystemV (SysVinit)
it has many limitations like performance problem which is mainly due to the fact that it can perform only one startup task/process at a time (no parallel startup). Another limitation is the fact that it can start a fixed set of services as defined by the boot sequence.
/etc/init.d
rouhani@cassius ~ $ ps -ef | grep init
root 1 0 0 Oct09 ? 00:00:25 /sbin/init showopts
Maybe one of the important concept here is runlevel which is denoted by a number from 0 to 6. It basically means a state of the machine which a certain set of processes is running.
2. Systemd
it is emerging standard which many distributions have moved to it. It also has a pid=1 and is the parent (directly or indirectly) of all other processes. Usually when system has following 2 directories, it has systemd:
- /usr/lib/systemd
- /etc/systemd
[root@puppetserver ~]# ps -ef | grep systemd
root 1 0 0 Oct09 ? 00:00:04 /usr/lib/systemd/systemd –switched-root –system –deserialize 21
One of the main feature of it is its ability to defer the start of services and OS features until it is necessary.
3.Upstart
which is a init in Ubuntu systems and probably we have /etc/init directory that contains several files. Here we can easily see the list of upstart jobs and status by following command:
# initctl list
In order to control a job here we can use following commands:
# initctl start job
# initctl stop job
# initctl restart job
