Introduction
The General Parallel File System (GPFS) is a high-performance clustered file system developed by IBM. It is described as a parallel file system because GPFS data is broken into blocks and striped across multiple disks in an array, then read in parallel when data is accessed. This allows for faster read and write speeds. It also has lots of enterprise features such as High availability, replication, mirroring and disaster recovery.
Basically there are several ways of having this parallel file-system:
a. Software only: which basically means we can only get the GPFS software (Express, Standard or Advanced edition) and install it in any Hardware we have. I will go through the configuration of this type here.
b. Special Hardware that designed for this:
-
ESS from IBM: Here we can take advantage of IBM Spectrum Scale RAID software which is in NSD servers side and do not have anything to do with Jbod.
- GSS from lenovo
-
NEC
There are several topologies:
- Shared storage Model (SAN)
- Client & Server Model (still can have shared storage even with SAN)
- Shared nothing cluster model(SNC): Each server has local disk which is very useful for Big Data
The one which is mostly used in HPC area is client & server model which can be seen in the following figure. Here we can have any kind of storage, SAN or NAS. In this topology we have 3 entities:
- NSD client
- NSD servers (I/O servers)
- NSD (Disks)

Take into consideration that both NSD client and NSD server has GPFS daemon and only their responsibilities are different. So basically we have to install same GPFS rpms in all systems which are part of GPFS cluster.
The storage side consist of Metadata Disks and Storage (real data) Disks. So NSD servers basically serve both Metadata/Storage requests.
As I mentioned earlier, there are lots of enterprise features in GPFS software. Maybe one of the common feature that is used a lot is Fail-over concept. Here we can have Active/Active Fail-over for NSD servers as can be seen in the following photo.

The NSD servers can replicate metadata and data (up to 3 copies) if configured. The replication is based on failure groups, and 2 failure group are required at least for this configuration. Take into consideration that replication and failure group are 2 different concept and should not be confused.
General Concepts
All nodes which are part of the GPFS cluster need to have GPFS software (rpms) installed. It is a multi-threaded daemon (user mode daemon) which has a special Kernel extension. The purpose of the kernel extension is that GPFS appears to the application as just another file-system. Off course here the OS is using the concept of Virtual File system.
Description:
The virtual file system (VFS) interface, also known as the v-node interface, provides a bridge between client applications and a real file-system (which is GPFS in our case) in a way that application think of having access to local file-system. So basically it is a abstraction layer which shield the underlying file-system differences and plus provides the opportunity for the kernel to support new file-system.
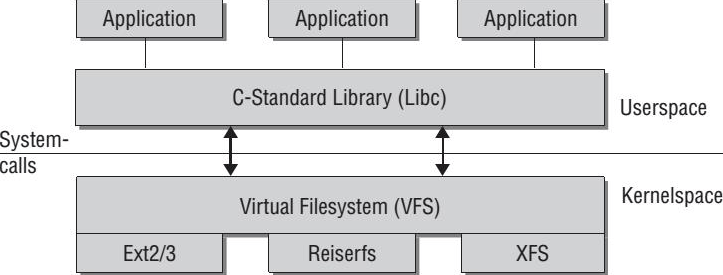
So to make it fully understandable, let’s summarize and categorize the whole concept here. Following is GPFS structure:
a. Linux Kernel
b. GPFS portability layer: It is a layer (loadable kernel module) which enables communication between Linux kernel (OS) and GPFS daemon. This kernel module must be compiled after GPFS installation since it can be unique for each architecture, distribution and kernel.
c. GPFS kernel extension: It provides the interfaces to the OS virtual file-system (VFS) in order to add the GPFS file-system. So simply the OS think of GPFS file-system as another local file-system like ext3 or xfs.
d. GPFS daemon: The GPFS daemon performs all I/O and buffer management for GPFS. This includes read-ahead for sequential reads and write-behind for all writes not specified as synchronous.
Description
read-ahead is a system call of the Linux kernel that loads a file’s contents into the page cache. This prefetches the file so that when it is subsequently accessed, its contents are read from the RAM rather than from a Harddisk (HDD), resulting in much lower file access latencies. (wiki)
There are two basic writing approaches:
- Write-through: write is done synchronously both to the cache and to the backing store.
-
Write-back (also called write-behind): initially, writing is done only to the cache. The write to the backing store is postponed until the cache blocks containing the data are about to be modified/replaced by new content.

So I can define following stages for GPFS:
1. Application make file-system calls to the OS
2. OS will pass the calls to the GPFS kernel extension
obviously (since it connected via VFS)
3. GPFS kernel extension will decide:
a. if it has the requested resources (available in the system), then reply back .
b. otherwise pass the call to GPFS daemon with the help of GPFS portability layer for this communication
Cluster configuration
There would be a configuration file which is replicated on all nodes in the cluster. The file is stored in following directory:
/var/mmfs/gen/mmsdrfs
which contains list of nodes, available disks, file-system and all other cluster configurations. There are 2 ways to store cluster configuration data:
a. Traditional server-based configuration repository.
mmchcluster {[--ccr-disable] [-p PrimaryServer] [-s SecondaryServer]}
Any configuration changes require primary and secondary server be available.
b. Using Configuration server repository (CCR) which stores redundant copies of configuration files on all quorum nodes. The advantage of CCR over the traditional way is that when using CCR, all GPFS administration commands as well as file system mounts and daemon startups work normally as long as a majority of quorum nodes are accessible.
mmchcluster --ccr-enable
Any configuration changes require majority of Quorum nodes to be available.
Installation and configuration of the GPFS file-system – Steps to follow
1. we first install some perquisite packages, specially needed when creating portability layer.
- Kernel-devel
- gcc
- gcc-c++
- make
- ksh
- ..
- ..
better to install complete Development packages in Centos
2. Install standard edition including following packages:(rpm -ivh …)
- gpfs.base-4.2.1-2.x86_64.rpm
- gpfs.ext-4.2.1-2.x86_64.rpm
- gpfs.msg.en_US-4.2.1-2.noarch.rpm
- gpfs.docs-4.2.1-2.noarch.rpm
- gpfs.gpl-4.2.1-2.noarch.rpm
- gpfs.gskit-8.0.50-57.x86_64.rpm
3. Add all GPFS commands into path. So we can do following 2steps:
- a. echo ‘export PATH=$PATH:/usr/lpp/mmfs/bin/’ >> ~/.bashrc that at next reboot we have all commands
- b. to make it effective immediately only on our session export PATH=$PATH:/usr/lpp/mmfs/bin/
4. Building the portability layer on all nodes. There are 2 ways of doing that:
a. using following command: mmbuildgpl
Don’t forget the commands are in /usr/lpp/mmfs/bin in case its not already in your environment. If we want to create installable package we can use following command: (in newer version of GPFS is only available)
/usr/lpp/mmfs/bin/mmbuildgpl --build-package
b. We can use following command using Autoconfig tool:
- cd /usr/lpp/mmfs/src
- make Autoconfig
- make World
- make InstallImages
- make rpm (this is for case which is redhat dist)
When the command finishes, it displays the location of the generated package.
5. DNS is very important in GPFS configuration. Make sure all nodes can resolve properly the name and IP add of all other NSD servers and nodes. Since I used xCAT statefull for NSD servers deployment, everything works perfectly. Otherwise we must put the name and IP add in /etc/hosts of all nodes.
6. Password-less authentication among all nodes based on ssh-keys. I used xCAT, so all already configured. Otherwise we can easily use “ssh-keygen” on each node to generate the key and then use following command to send the public-key to other nodes:
“ssh-copy-id -i public-key <node-name>”
The important point is that we need to do it for LocalHost as well. This means that when we do “ssh localhost”, it should not prompt for password.
7. Make sure SELinux is disabled in all nodes using “getenforce” command. Also make sure firewall is disbaled in all nodes which basically means iptables and firewald for Redhat.
8. GPFS cluster creation
There is a command “mmcrcluster” that will help us to create the cluster. There are several options that can be used with this command. I describe several important options before I write the command.
a. Node role: In general we have 2 categories of node.
a.1 Manager or Client: Indicates whether a node is part of the node pool from which file system managers and token managers can be selected. Keep it in mind that by default it is client and will not participate in this pool. How many nodes you designate as manager depends on the workload and the number of GPFS server licenses you have.
The task of file-system manager are:
- File system configuration like adding disks, changing disk availability and repairing the file-system.
- Management of disk space allocation.
- Token management. The token management server coordinates access to files on shared disks by granting tokens that convey the right to read or write the data or metadata of a file. This service ensures the consistency of the file system data and metadata when different nodes access the same file.
- Quota management.
a.2 quorum or non-quorum: This designation specifies whether or not the node should be included in the pool of nodes from which quorum is derived. The default is non-quorum.
b. Have to define whether we use Primary/Secondary kind of configuration or using CCR. If we use Primary/secondary kind we need to define which server is primary and which one is secondary and disable the CCR.
c. When we run the “mmcrcluster” we need to define the Remote copy program as well as the Shell command. Here I will use “scp” and “ssh” for this purpose with using complete path.
d. Some information like ClusterName and Cluster node (NSD servers) are important.
So at the end we will have following command which need to be run on only one node:
mmcrcluster -N node1:manager-quorum,node2:manager-quorum,node3:manager-quorum,… –ccr-enable -r /usr/bin/ssh -R /usr/bin/scp -C mycluster
- manager-quorum means the node is both manager and part of the quorum.
if we want to use primary and secondary kind of configuration (-p for primary and -s for secondary):
mmcrcluster -N node1:manager-quorum,node2:manager-quorum, node3:manager-quorum,… –ccr-disable -p node1 -s node2 -r /usr/bin/ssh -R /usr/bin/scp -C mycluster
Upon successful completion of the mmcrcluster command, the /var/mmfs/gen/mmsdrfs and the /var/mmfs/gen/mmfsNodeData files are created on each of the nodes in the cluster. Do not delete these files under any circumstances.
9. Set the license mode for each node-name
mmchlicense server --accept -N node1,node2,node3,… * we specified that the nodes are all Server here. [root@g2_node1 ~]# mmlslicense Summary information --------------------- Number of nodes defined in the cluster: 2 Number of nodes with server license designation: 2 Number of nodes with client license designation: 0 Number of nodes still requiring server license designation: 0 Number of nodes still requiring client license designation: 0 This node runs IBM Spectrum Scale Standard Edition
10. Check the cluster state and start the cluster when required.
To check the cluster state use the command: mmgetstate -a
- active: GPFS is ready for operations.
- Arbitrating: A node is trying to form a quorum with the other available nodes.
- Down: GPFS daemon is not running on the node or is recovering from an internal error.
- Unknown: Unknown value. Node cannot be reached or some other error occurred
To display summary information, issue this command:
- mmgetstate -s
To start the cluster use the command:
- mmstartup -a
To check your cluster configuration use the command:
- mmlscluster
To verify which interface is being used for cluster communication use the command:
- mmdiag –network
11. Create network shared disks (NSDs). We use a special command called “mmcrnsd” for this purpose. This command is used to create cluster-wide names for NSDs used by GPFS. The input to this command consists of a file containing NSD stanzas describing the properties of the disks to be created.
So the command is as follow:
- mmcrnsd -F StanzaFile [-v {yes | no}]
The main part of this command is Stanza file which contains the properties of the disks to be created. This command must be run for all disks that are to be used in GPFS file systems. The mmcrnsd command is also used to assign each disk an NSD server list that can be used for I/O operations on behalf of nodes that do not have direct access to the disk. After the NSDs are created, the GPFS cluster data is updated and they are available for use by GPFS.
The stanza file has following format:
%nsd: device=DiskName
nsd=NsdName
servers=ServerList
usage={dataOnly | metadataOnly | dataAndMetadata | descOnly | localCache}
failureGroup=FailureGroup
pool=StoragePool
a. device=DiskName.On UNIX, the block device name appearing in /dev for the disk you want to define as an NSD.
b. nsd=NsdName. Specify the name you desire for the NSD to be created. Please do not confused NSD with NSD server which is server I/O.
c. servers=ServerList. Is a comma-separated list of NSD server nodes. You may specify up to eight NSD servers in this list. The defined NSD will preferentially use the first server on the list. If the first server is not available, the NSD will use the next available server on the list.
There are two cases where a server list either must be omitted or is optional:
-
For IBM Spectrum Scale RAID, a server list is not allowed. The servers are determined from the underlying vdisk definition
-
For SAN configurations where the disks are SAN-attached to all nodes in the cluster, a server list is optional.
- d. usage={dataOnly | metadataOnly | dataAndMetadata | descOnly | localCache}
- Specifies the type of data to be stored on the disk:
- dataAndMetadata: Indicates that the disk contains both data and metadata. This is the default for disks in the system pool.
- dataOnly: Indicates that the disk contains data and does not contain metadata. This is the default for disks in storage pools other than the system pool.
- metadataOnly: Indicates that the disk contains metadata and does not contain data.
- LocalCache: Indicates that the disk is to be used as a local read-only cache device.
e. failureGroup=FailureGroup. A number identifying the failure group to which this disk belongs. All disks that are either attached to the same adapter or virtual shared disk server have a common point of failure and should therefore be placed in the same failure group. In other words, A failure group is a set of disks that share a common point of failure that could cause them all to become simultaneously unavailable. Take into consideration the number is just for the sake of similarity between several NSD and does not represent anything.
We should not confuse failure group with replication factor that we define separately in GPFS. We define a replication factor to indicate the total number of copies of data and metadata we wish to store. Replication allows you to set different levels of protection for each file or one level for an entire file system. It is usually the case that administrators consider replication factor only for Metadata, due to disk capacity.
The concept of failure group and replication factor can be used in conjunction which means GPFS maintains each instance of replicated data and metadata on disks in different failure groups.
A replication factor of two in GPFS means that each block of a replicated file is in at least two failure groups. A failure group is defined by the administrator and contains one or more NSDs. Each storage pool in a GPFS file system contains one or more failure groups. Failure groups are defined by the administrator and can be changed at any time. So when a file system is fully replicated any single failure group can fail and the data remains online.
g. StoragePool Specifies the name of the storage pool that the NSD is assigned to. One of these storage pools is the required “system” storage pool. The other internal storage pools are optional user storage pools. An example I put here:
%nsd: device=/dev/mapper/fs1sas0
nsd=data10
servers=ffs1-ib,ffs2-ib,ffs3-ib,ffs4-ib,ffs5ib,ffs6-ib
usage=dataOnly
failureGroup=1
pool=system
%nsd: device=/dev/mapper/fs1sas1
nsd=data11
servers=ffs1-ib,ffs2-ib,ffs3-ib,ffs4-ib,ffs5ib,ffs6-ib
usage=dataOnly
failureGroup=1
pool=system
%nsd: device=/dev/mapper/fs1sas2
nsd=data12
servers=ffs1-ib,ffs2-ib,ffs3-ib,ffs4-ib,ffs5ib,ffs6-ib
usage=dataOnly
failureGroup=1
pool=system
Quorum operates on the principle of majority rule. This means that a majority of the nodes in the cluster must be successfully communicating before any node can mount and access a file system. This keeps any nodes that are cut off from the cluster (for example, by a network failure) from writing data to the file system.
During node failure situations, quorum needs to be maintained in order for the cluster to remain online. If quorum is not maintained due to node failure, GPFS unmounts local file systems on the remaining nodes and attempts to reestablish quorum, at which point file system recovery occurs. For this reason it is important that the set of quorum nodes be carefully considered.
GPFS quorum must be maintained within the cluster for GPFS to remain active. If the quorum semantics are broken, GPFS performs recovery in an attempt to achieve quorum again. GPFS can use one of two methods for determining quorum.
Based on Quorum Rules cluster decides whether it is safe to continue I/O operations in the case of a communication failure between cluster nodes:
- Prevent “Split-Brain” situations
- Maintain data consistency in the cluster
- Cluster nodes can be assigned Quorum role (requires server license)
- Quorum rule: (N/2)+1 quorum nodes must be active (N # of quorum nodes)
- When quorum rule is not met, GPFS shuts down (un-mounts file systems)
***************************************************************************
Real GPFS Installation and Configuration
Here I will go through configuring a real example which I encountered through a big project somewhere in Europe. The cluster includes:
- 1 Master node (xCAT master node redhat 7.2)
- 1 Slurm Master node (redhat 7.2)
- 408 Compute nodes (statefull redhat 7.2)
- 6 NSD servers (installed with Redhat 7.2)
– 2 Dual-port 56Gbps IB HCA (Mellanox)
– 3 Dual-port 16Gb FC HBA
- 6 Storage Block -oceanstore huawei (5800V3)
– 96 * 900GB 10k rpm
– 4 * SSD 400GB (raid 10 in each storage block)
- FC switch: oceanstore SNS2224
So in order to have a better control over GPFS and make the administration tasks easier, we have decided to have 2 GPFS domain. One for NSD server/Storage block side and one for Compute node side. Off course the compute node side does not have NSDs or NSD servers.
Also we have 6 LUN for data and 2 LUN for metadata in each storage block.
a. Storage side GPFS
WE have 6 NSD servers. We put all 6 NSD servers as quroum nodes but based on the rules (n/2)+1 have to be active, which basically means until 2 NSD servers failur can be OK. So first we created a file with the name of NSD servers:
1) create the cluster:
#cat cluster_nodes
nsd1-ib:quorum-manager
nsd2-ib:quorum-manager
nsd3-ib:quorum-manager
nsd4-ib:quorum-manager
nsd5-ib:quorum-manager
nsd6-ib:quorum-manager
So all of them are both Manager and participating in quorum. Since we want the daemon communication (GPFS management communication) happens through IpoIB, therefore we used the nsd*-ib names of the NSD servers which are refering to ipoib IP address of each node. Please take into consideration that DNS is fully functional in xCAT master nodes. So all Nsd servers can resolve the Name/IP easily of each other without any problem.
2) creating the cluster
As we know it doesn’t matter from which node we initiate our commands in GPFS cluster. Here I choose the first NSD server called nsd1. The idea is to use CCR so we need to enable it.
[root@nsd1]# mmcrcluster -N cluster_nodes –ccr-enable -r /usr/bin/ssh -R /usr/bin/scp -C hrouhani.storage
mmcrcluster: Performing preliminary node verification …
Warning: Permanently added ‘nsd1-ib.hrouhani’ (ECDSA) to the list of known hosts.
mmcrcluster: Processing quorum and other critical nodes …
mmcrcluster: Finalizing the cluster data structures …
mmcrcluster: Command successfully completed
mmcrcluster: Warning: Not all nodes have proper GPFS license designations.
Use the mmchlicense command to designate licenses as needed.
mmcrcluster: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
Then we can check the status of cluster creation:
[root@nsd1 gpfs]# mmlscluster
GPFS cluster information
========================
GPFS cluster name: hrouhani.storage
GPFS cluster id: 9237173280089979847
GPFS UID domain: hrouhani.storage
Remote shell command: /usr/bin/ssh
Remote file copy command: /usr/bin/scp
Repository type: CCR
Node Daemon node name IP address Admin node name Designation
——————————————————————
1 nsd1-ib.hrouhani 172.23.1.1 nsd1-ib.hrouhani quorum-manager
2 nsd2-ib.hrouhani 172.23.1.2 nsd2-ib.hrouhani quorum-manager
3 nsd3-ib.hrouhani 172.23.1.3 nsd3-ib.hrouhani quorum-manager
4 nsd4-ib.hrouhani 172.23.1.4 nsd4-ib.hrouhani quorum-manager
5 nsd5-ib.hrouhani 172.23.1.5 nsd5-ib.hrouhani quorum-manager
6 nsd6-ib.hrouhani 172.23.1.6 nsd6-ib.hrouhani quorum-manager
3) We might get some warning in previous steps regarding license.
[root@nsd1 gpfs]# mmchlicense server –accept -N nsd1-ib,nsd2-ib,nsd3-ib,nsd4-ib,nsd5-ib,nsd6-ib
4) Some important tunning before continuing. First we need to tell the GPFS that we want all data I/O happens through RDMA
[root@nsd1 gpfs]# mmchconfig verbsRdma=enable
and then we need to tell GPFS the mellanox cards and ports that need to be used in this storage GPFS cluster. And we need to tell in which fabric subnet they need to work.
As can be seen in each NSD servers we have 2 Mellanox cards which each has 2 ports. Here we used one port in each card due to higher bandwidth.
[root@nsd1 ~]# ibstat
CA ‘mlx4_0’
CA type: MT4099
Number of ports: 2
Firmware version: 2.36.5150
Hardware version: 1
Node GUID: 0x248a070300606c00
System image GUID: 0x248a070300606c03
Port 1:
State: Active
Physical state: LinkUp
Rate: 56
Base lid: 453
LMC: 0
SM lid: 465
Capability mask: 0x02514868
Port GUID: 0x248a070300606c01
Link layer: InfiniBand
Port 2:
State: Down
Physical state: Polling
Rate: 10
Base lid: 479
LMC: 0
SM lid: 465
Capability mask: 0x02514868
Port GUID: 0x248a070300606c02
Link layer: InfiniBand
CA ‘mlx4_1’
CA type: MT4099
Number of ports: 2
Firmware version: 2.36.5150
Hardware version: 1
Node GUID: 0x248a070300606c20
System image GUID: 0x248a070300606c23
Port 1:
State: Active
Physical state: LinkUp
Rate: 56
Base lid: 456
LMC: 0
SM lid: 465
Capability mask: 0x02514868
Port GUID: 0x248a070300606c21
Link layer: InfiniBand
Port 2:
State: Down
Physical state: Polling
Rate: 10
Base lid: 471
LMC: 0
SM lid: 465
Capability mask: 0x02514868
Port GUID: 0x248a070300606c22
Link layer: InfiniBand
The following command tell how storage GPFS is going to use mellanox cards. The */*/* is the pattern we use here and the last number which is 2 here will tell that they are in same fabric subnet.
- [root@nsd1# mmchconfig verbsPorts=”mlx4_0/1/2 mlx4_1/1/2″
- mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all affected nodes.This is an asynchronous process.
- [root@nsd1]# mmlsconfig
Configuration data for cluster hrouhani.storage:
———————————————
clusterName hrouhani.storage
clusterId 9237173280089979847
autoload no
dmapiFileHandleSize 32
minReleaseLevel 4.2.1.1
ccrEnabled yes
cipherList AUTHONLY
verbsRdma enable
verbsPorts mlx4_0/1/2 mlx4_1/1/2
adminMode central File systems in cluster hrouhani.storage:
————————————–
(none)
and then we set the important flag which is sochetMaxListenConnections
[root@nsd1 gpfs]# mmchconfig socketMaxListenConnections=1024
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
Definition:
socketMaxListenConnections
Definition: The maximum length of the TCP listen queue backlog of incoming connections requests for the socket used by the GPFS listen thread.
Default Value: AIX: 1024 Linux: 128
Minimum and Maximum Value: 1 and 65536
Recommended Value: Set the value of socketMaxListenConnections greater than or equal to the number of nodes that will create a TCP connection to any one node.
5) So now we can start the the Storage GPFS cluster
[root@nsd1 gpfs]# mmstartup -a
and can get the status of them by following command (it takes some times to become active from arbitrating)
[root@nsd1 gpfs]# mmgetstate -a
Node number Node name GPFS state
——————————————
1 nsd1-ib active
2 nsd2-ib active
3 nsd3-ib active
4 nsd4-ib active
5 nsd5-ib active
6 nsd6-ib active
6) during above steps, if you faced with any problems, can easily check the logs
[root@nsd1 gpfs]# cat /var/adm/ras/mmfs.log.latest
7) Now we need to create the NSDs. For this we have to write the stanza file. As I mentioned earlier, we have 6 Storage blocks which connected through Fiber channel to NSD servers. For 2 reasons, we have decided to create 6 LUN for each Storage blocks:
7.1) in case of NSD server failures, if we have only 1 LUN, there would be very high load to the NSD server that taking over. But when we have 6 LUN, we can distribute them to different NSD servers (we do it with stanza file)
7.2) better performance
Here we use multipath that make our task much easier. So basically we have a multipath.conf file that do this mapping for us as can be seen here:
[root@nsd1 ~]# cat /etc/multipath.conf
## defaults section
defaults {
rr_weight priorities
failback immediate
user_friendly_names yes
find_multipaths yes
}
# Generic for Huawei
devices {
device {
vendor “HUAWEI ”
product “XSG1”
path_grouping_policy multibus
path_checker tur
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
}
blacklist {
devnode “^(ram|raw|loop|fd|md|dm-|sr|scd|st)[0-9]*”
devnode “^hd[a-z]”
device {
vendor “LSI”
product”*”
}
}
# definition for fs3 follows
###############################
multipath {
wwid 3648d539100c427a4001f763200000000
alias fs3ssd0
path_grouping_policy multibus
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f76b100000001
alias fs3ssd1
path_grouping_policy multibus
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f94e000000002
alias fs3sas0
path_grouping_policy multibus
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f94fb00000003
alias fs3sas1
path_grouping_policy multibus
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f952c00000004
alias fs3sas2
path_grouping_policy multibus
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f954600000005
alias fs3sas3
path_grouping_policy multibus
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f957900000006
alias fs3sas4
path_grouping_policy multibus
path_selector “round-robin 0”
failback immediate
rr_weight priorities
}
multipath {
wwid 3648d539100c427a4001f959400000007
alias fs3sas5
path_grouping_policy multibus
rr_weight priorities
}
##############################
# definition for fs2-6 also sth similar …
##############################
so if we look at the configuration more carefully we can see following:
[root@nsd1 ~]# multipath -ll | grep HUAWEI | awk ‘{print $1}’ | sort
fs1sas0
fs1sas1
fs1sas2
fs1sas3
fs1sas4
fs1sas5
fs1ssd0
fs1ssd1
….
….
….
So basically for each storage block we have 6 lun for data and 2 lun for metadata (ssd). To get even better understanding of the situation, we can have a look at there:
[root@nsd1 ~]# ll /dev/mapper/
total 0
crw——- 1 root root 10, 236 Jan 12 12:03 control
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1sas0 -> ../dm-18
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1sas1 -> ../dm-19
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1sas2 -> ../dm-20
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1sas3 -> ../dm-21
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1sas4 -> ../dm-22
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1sas5 -> ../dm-23
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1ssd0 -> ../dm-16
lrwxrwxrwx 1 root root 8 Jan 18 15:15 fs1ssd1 -> ../dm-17
…
…
…
Now lets create stanza file for creating the NSDs. Each nsd should have a unique name, so I used data** schema. Since only 2 NSD servers can fail due to quroum numbers, in the servers list we have only 2 servers name. The device /dev/mapper/* is corresponding only to first server in the list which here is nsd1-ib. Here I want to use ipoib for daemon and management communication, therefore we used nsd*-ib name whis resolving with DNS server to ipoib IP address of each NSD servers.
[root@nsd1 gpfs]# cat stanza.nsds
#*******************************************
#***** Block storage 1 **********
# If storage block 1 fails all its nsds will be unavailable. So we need to put all of them in a same failure group. By default GPFS is sending data to “system” pool, thats why afterward we need to tell GPFS that please send data to “data” pool by a policy.
%nsd: device=/dev/mapper/fs1sas0
nsd=data10
servers=nsd1-ib,nsd2-ib
usage=dataOnly
failureGroup=1
pool=data
%nsd: device=/dev/mapper/fs1sas1
nsd=data11
servers=nsd1-ib,nsd3-ib
usage=dataOnly
failureGroup=1
pool=data
%nsd: device=/dev/mapper/fs1sas2
nsd=data12
servers=nsd1-ib,nsd4-ib
usage=dataOnly
failureGroup=1
pool=data
%nsd: device=/dev/mapper/fs1sas3
nsd=data13
servers=nsd1-ib,nsd5-ib
usage=dataOnly
failureGroup=1
pool=data
%nsd: device=/dev/mapper/fs1sas4
nsd=data14
servers=nsd1-ib,nsd6-ib
usage=dataOnly
failureGroup=1
pool=data
%nsd: device=/dev/mapper/fs1sas5
nsd=data15
servers=nsd1-ib,nsd2-ib
usage=dataOnly
failureGroup=1
pool=data
%nsd: device=/dev/mapper/fs1ssd0
nsd=meta10
servers=nsd1-ib,nsd2-ib
usage=metadataOnly
failureGroup=1
pool=system
%nsd: device=/dev/mapper/fs1ssd1
nsd=meta11
servers=nsd1-ib,nsd3-ib
usage=metadataOnly
failureGroup=1
pool=system
****************************************************
***** Block storage 2 **********
%nsd: device=/dev/mapper/fs2sas0
nsd=data20
servers=nsd2-ib,nsd3-ib
usage=dataOnly
failureGroup=2
pool=data
%nsd: device=/dev/mapper/fs2sas1
nsd=data21
servers=nsd2-ib,nsd4-ib
usage=dataOnly
failureGroup=2
pool=data
%nsd: device=/dev/mapper/fs2sas2
nsd=data22
servers=nsd2-ib,nsd5-ib
usage=dataOnly
failureGroup=2
pool=data
%nsd: device=/dev/mapper/fs2sas3
nsd=data23
servers=nsd2-ib,nsd6-ib
usage=dataOnly
failureGroup=2
pool=data
%nsd: device=/dev/mapper/fs2sas4
nsd=data24
servers=nsd2-ib,nsd1-ib
usage=dataOnly
failureGroup=2
pool=data
%nsd: device=/dev/mapper/fs2sas5
nsd=data25
servers=nsd2-ib,nsd3-ib
usage=dataOnly
failureGroup=2
pool=data
%nsd: device=/dev/mapper/fs2ssd0
nsd=meta20
servers=nsd2-ib,nsd3-ib
usage=metadataOnly
failureGroup=2
pool=system
%nsd: device=/dev/mapper/fs2ssd1
nsd=meta21
servers=nsd2-ib,nsd4-ib
usage=metadataOnly
failureGroup=2
pool=system
****************************************************
***** Block storage 3-6 same procedure**********
and Then afterward create the NSDs with above stanza file:
[root@nsd1]# mmcrnsd -F stanza.nsds -v no
We got error that couldn’t find the /dev/mapper/* inside the /proc/partitions. So basically GPFS couldn’t realize our schema of /dev/mapper. To solve this problem we need to write the following script which must be copied in all NSD servers.
Description:
Some customer like us prefer to use the multipath friendly names (i.e. /dev/mapper/mapth*) because those names do not change after reboots. To make GPFS aware of those devices (that does not exits under /proc/partitions), you will need to use the nsddevices script to echo those devices. The nsddevices script will be invoked by the GPFS daemon when discovering or verifying
# cp /usr/lpp/mmfs/samples/nsddevices.sample /var/mmfs/etc/nsddevices
# chmod u+x /var/mmfs/etc/nsddevices
** don’t forget to include this file in xCAT postscript if you want to reinstall the servers from scratch again in the future.**
[root@nsd1]# cat /var/mmfs/etc/nsddevices
#############################
osName=$(/bin/uname -s)
if [[ $osName = Linux ]]
then
: # Add function to discover disks in the Linux environment.
ls -l /dev/mapper/ 2>/dev/null | awk ‘{print “mapper/”$9 ” generic”}’
fi
if [[ $osName = AIX ]]
then
: # Add function to discover disks in the AIX environment.
fi
and then run again the above command for creating the NSDs.
[root@nsd1 gpfs]# mmcrnsd -F stanza.nsds -v no
mmcrnsd: Processing disk mapper/fs1sas0
mmcrnsd: Processing disk mapper/fs1sas1
mmcrnsd: Processing disk mapper/fs1sas2
..
..
and then check if we can see all NSDs (the name is data**)
[root@nsd1 gpfs]# mmlsnsd
File system Disk name NSD servers
—————————————————————————
(free disk) data10 nsd1-ib.hrouhani,nsd2-ib.hrouhani
(free disk) data11 nsd1-ib.hrouhani,nsd3-ib.hrouhani
(free disk) data12 nsd1-ib.hrouhani,nsd4-ib.hrouhani
…
…
…
if during creating NSDs we faced with any problems, and need to delete all NSDs and create it again, we can use mmdelnsd command. But first we need to get the list of all NSDs.
[root@nsd1 gpfs]# mmlsnsd | awk ‘{print $3’} > dellist.txt
and then
[root@nsd1 gpfs]# mmdelnsd -F dellist.txt
and then create again with stanza file.
8) then we do some tunning:
[root@nsd1 ~]# mmchconfig PagePool=8G
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
[root@nsd1 ~]# mmchconfig workerThreads=96 (2 times number of LUNS)
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
9) Creating the file-system
The following command is used for this purpose:
[root@nsd1]# mmcrfs gpfs_scratch -F stanza.nsds -j cluster -Q yes -A no -B 1m -M 2 -m 2 -R 2 -r 1 -n 512 -i 4k –inode-limit 50000000:50000000 -T /scratch –metadata-block-size 64k
The decsription of the flags that we used can be seen here.
-Q Quotas accounting enabled
-A Automatic mount option which disabled here.
-B it defines our data block size which is 1m
–metadata-block-size it defines the metadata block size which is 64K. At first we have choosen 256K and it turns out that file creation related to ssd is very slow. Therefore we changed the size to 64K. I will post the result of “mdtest” bechmark later.
-m Default number of metadata replicas which here me wrote 2 which basically replicate metadata.
-M Maximum number of metadata replicas. This is Only maximum allowed.
-r Default number of data replicas which is 1 here and means we don’t want replication.
-R Maximum number of data replicas allowed. Here we just put 2.
-n Estimated number of nodes that will mount file system
-i is the inode size which we chose a big one since if the file is very small, GPFS can save the whole file
in Metadata disks which is a very good advantage.
–inode-limit Maximum number of inodes
-T Default mount point and this directory is created automatically.
-j type of allocation methods which are cluster or scatter
When allocating blocks for a given file, GPFS first uses a round-robin algorithm to spread the data across all of the disks in the file system. After a disk is selected, the location of the data block on the disk is determined by the block allocation map type.
scatter: GPFS chooses the location of the blocks randomly.
** at first we have choosen Cluster mode, but performance was dramatically low**
10) before mounting the file-system manually since we deactivate the automatic one, we check the status of our configuration
[root@nsd1]# mmlsdisk gpfs_scratch
disk driver sector failure holds holds storage
name type size group metadata data status availability pool
———— ——– —— ———– ——– —– ————- ———— ————
data10 nsd 512 1 No Yes ready up data
data11 nsd 512 1 No Yes ready up data
data12 nsd 512 1 No Yes ready up data
data13 nsd 512 1 No Yes ready up data
data14 nsd 512 1 No Yes ready up data
data15 nsd 512 1 No Yes ready up data
meta10 nsd 512 1 Yes No ready up system
meta11 nsd 512 1 Yes No ready up system
….
….
….
and also following command for seeing the configuration
[root@nsd1]# mmlsfs gpfs_scratch
flag value description
——————- ———————— ———————————–
-f 8192 Minimum fragment size in bytes (system pool)
32768 Minimum fragment size in bytes (other pools)
-i 4096 Inode size in bytes
-I 32768 Indirect block size in bytes
-m 2 Default number of metadata replicas
-M 2 Maximum number of metadata replicas
-r 1 Default number of data replicas
-R 2 Maximum number of data replicas
-j cluster Block allocation type
-D posix File locking semantics in effect
-k posix ACL semantics in effect
-n 512 Estimated number of nodes that will mount file system
-B 65536 Block size (system pool)
1048576 Block size (other pools)
11) and finally mounting the file-system
[root@nsd1]# mmmount gpfs_scratch
Wed Jan 18 10:18:03 CET 2017: mmmount: Mounting file systems …
[root@nsd1]# mount
….
gpfs_scratch on /scratch type gpfs (rw,relatime)
[root@nsd1]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
gpfs_scratch gpfs 375T 2.3G 375T 1% /scratch
…
12) And now we have to tell GPFS that by default use our “data” pool for data and not “system” pool. So we use a policy for this one:
[root@nsd1]# cat scratch_gpfs.policy
RULE ‘default’ SET POOL ‘data’
[root@nsd1]# mmchpolicy gpfs_scratch scratch_gpfs.policy -I yes
Validated policy ‘scratch_gpfs.policy’: Parsed 1 policy rules.
Policy `scratch_gpfs.policy’ installed and broadcast to all nodes
13) and now testing the /scratch mount point to be sure all is OK.
[root@nsd1]# dd if=/dev/zero of=/scratch/test bs=1M count=10000
10000+0 records in
10000+0 records out
10485760000 bytes (10 GB) copied, 6.06805 s, 1.7 GB/s
Important: During configuration of GPFS, several files will be written to the local disk of the NSd servers. So it means that if any of NSD servers is dead for any reason and we want reinstall it, somehow we need to restore the configuration files. It is also the case if we want to re-install the NSd server completely from scratch through xCAT. we can use following commands for this purpose:
scp ${NSD-server}:/var/mmfs/ssl/stage/* /var/mmfs/ssl/stage/
/usr/lpp/mmfs/bin/mmsdrrestore -p ${NSD-server} -R /usr/bin/scp
NSD-server is the name of one of the NSD servers which should be up and available in order to get the data. First we copy the keys (ssl) and then with mmsdrrestore command will restore the data.
14) Tunning options we did here:
a. [root@nsd1 ~]# cat /etc/sysctl.d/gpfs.conf
# Allow more sockets for GPFS (greater or equal to socketMaxListenConnections)
net.core.somaxconn = 1024
# Leave 3% free mem for GPFS
vm.min_free_kbytes = 8388608
b. created a new file in following directoy in each NSD servers and fill it with optimized parameters:
[root@ffs1 ~]# cat /etc/udev/rules.d/99-block_device_settings-gpfs_scratch.rules
# NSD: data10 PATH: /dev/mapper/fs1sas0
SUBSYSTEM==”block”, KERNEL==”dm-*”, PROGRAM==”/lib/udev/scsi_id -g -u -d /dev/%k”, RESULT==”3648d539100c44025003a74df00000002″, RUN+=”/bin/sh -c ‘/bin/echo 1024 > /sys/block/%k/queue/max_sectors_kb; /bin/echo 1024 > /sys/block/%k/queue/read_ahead_kb; /bin/echo 256 > /sys/block/%k/queue/nr_requests; /bin/echo 32 > /sys/block/%k/device/queue_depth; /bin/echo noop > /sys/block/%k/queue/scheduler; ‘”
# NSD: data11 PATH: /dev/mapper/fs1sas1
SUBSYSTEM==”block”, KERNEL==”dm-*”, PROGRAM==”/lib/udev/scsi_id -g -u -d /dev/%k”, RESULT==”3648d539100c44025003a74f100000003″, RUN+=”/bin/sh -c ‘/bin/echo 1024 > /sys/block/%k/queue/max_sectors_kb; /bin/echo 1024 > /sys/block/%k/queue/read_ahead_kb; /bin/echo 256 > /sys/block/%k/queue/nr_requests; /bin/echo 32 > /sys/block/%k/device/queue_depth; /bin/echo noop > /sys/block/%k/queue/scheduler; ‘”
# NSD: data12 PATH: /dev/mapper/fs1sas2
SUBSYSTEM==”block”, KERNEL==”dm-*”, PROGRAM==”/lib/udev/scsi_id -g -u -d /dev/%k”, RESULT==”3648d539100c44025003a751900000004″, RUN+=”/bin/sh -c ‘/bin/echo 1024 > /sys/block/%k/queue/max_sectors_kb; /bin/echo 1024 > /sys/block/%k/queue/read_ahead_kb; /bin/echo 256 > /sys/block/%k/queue/nr_requests; /bin/echo 32 > /sys/block/%k/device/queue_depth; /bin/echo noop > /sys/block/%k/queue/scheduler; ‘”
# NSD: data13 PATH: /dev/mapper/fs1sas3
SUBSYSTEM==”block”, KERNEL==”dm-*”, PROGRAM==”/lib/udev/scsi_id -g -u -d /dev/%k”, RESULT==”3648d539100c44025003a752f00000005″, RUN+=”/bin/sh -c ‘/bin/echo 1024 > /sys/block/%k/queue/max_sectors_kb; /bin/echo 1024 > /sys/block/%k/queue/read_ahead_kb; /bin/echo 256 > /sys/block/%k/queue/nr_requests; /bin/echo 32 > /sys/block/%k/device/queue_depth; /bin/echo noop > /sys/block/%k/queue/scheduler; ‘”
# NSD: data14 PATH: /dev/mapper/fs1sas4
SUBSYSTEM==”block”, KERNEL==”dm-*”, PROGRAM==”/lib/udev/scsi_id -g -u -d /dev/%k”, RESULT==”3648d539100c44025003a755c00000006″, RUN+=”/bin/sh -c ‘/bin/echo 1024 > /sys/block/%k/queue/max_sectors_kb; /bin/echo 1024 > /sys/block/%k/queue/read_ahead_kb; /bin/echo 256 > /sys/block/%k/queue/nr_requests; /bin/echo 32 > /sys/block/%k/device/queue_depth; /bin/echo noop > /sys/block/%k/queue/scheduler; ‘”
# NSD: data15 PATH: /dev/mapper/fs1sas5
SUBSYSTEM==”block”, KERNEL==”dm-*”, PROGRAM==”/lib/udev/scsi_id -g -u -d /dev/%k”, RESULT==”3648d539100c44025003a757300000007″, RUN+=”/bin/sh -c ‘/bin/echo 1024 > /sys/block/%k/queue/max_sectors_kb; /bin/echo 1024 > /sys/block/%k/queue/read_ahead_kb; /bin/echo 256 > /sys/block/%k/queue/nr_requests; /bin/echo 32 > /sys/block/%k/device/queue_depth; /bin/echo noop > /sys/block/%k/queue/scheduler; ‘”
# we do the same in the file for othr nsd data2*, data3*,.. data6*
Important: we can do all of above steps also from xCAT through synclist file:
[root@fadmin1 postscripts]# cat /install/custom/install/rh/gpfs.synclist
/install/configuration/sysctl_gpfs.conf -> /etc/sysctl.d/gpfs.conf
/install/configuration/99-block_device_settings-gpfs_scratch.rules -> /etc/udev/rules.d/
/install/configuration/nsddevices -> /var/mmfs/etc/nsddevices
and also need to change the osimage definition that include synclist file:
[root@Master-node]# lsdef -t osimage -o rhels7-install-gpfs
Object name: rhels7-install-GPFS
imagetype=linux
osarch=x86_64
osdistroname=rhels7.2-x86_64
osname=Linux
osvers=rhels7.2
otherpkgdir=/install/post/otherpkgs/rhels7.2/x86_64
pkgdir=/install/rhels7.2/x86_64,/install/software/gpfs/4.2.1-2
pkglist=/install/custom/install/rh/gpfs.rhels7.pkglist
profile=gpfs
provmethod=install
synclists=/install/custom/install/rh/gpfs.synclist
template=/install/custom/install/rh/gpfs.rhels7.tmpl
**************************************************************************
b. Compute side GPFS
As I said before, we seperate compute node side from Storage side in GPFS. So here we will create a GPFS cluster for compute side which do not have any storage (NSDs).
1) first we need to have the list of all systems which will be part of this cluster which are Master node, Slurm master node and all 408 compute nodes. We save the names of all in a file called cluster_nodes
[root@admin1 ~]# xdsh compute hostname > cluster_nodes
and add -ib to the end of the names. Since we want also deamon/management communication goes through infiniband. Since we want to have Primary/secondary kind of configuration and not CCR, therefore we decided to put Master node and slurm master node as quorum-manager and node001 as only quorum.
[root@admin1 gpfs]# cat cluster_nodes
admin1-ib:quorum-manager
admin2-ib:quorum-manager
node001-ib:quorum
node002-ib
f003-ib
…
…
f408-ib
2) creating the Compute side GPFS cluster which is called hrouhani.compute here
[root@admin1 gpfs]# mmcrcluster -N cluster_nodes -C hrouhani.compute –ccr-disable -p admin1-ib -s admin2-ib
mmcrcluster: Performing preliminary node verification …
mmcrcluster: Processing quorum and other critical nodes …
mmcrcluster: Processing the rest of the nodes …
mmcrcluster: Finalizing the cluster data structures …
mmcrcluster: Command successfully completed
mmcrcluster: Warning: Not all nodes have proper GPFS license designations.
Use the mmchlicense command to designate licenses as needed.
mmcrcluster: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
[root@admin1 gpfs]# mmlscluster
GPFS cluster information
========================
GPFS cluster name: hrouhani.compute
GPFS cluster id: 11461824244720031482
GPFS UID domain: hrouhani.compute
Remote shell command: /usr/bin/ssh
Remote file copy command: /usr/bin/scp
Repository type: server-based
GPFS cluster configuration servers:
———————————–
Primary server: admin1-ib
Secondary server: admin2-ib
Node Daemon node name IP address Admin node name Designation
——————————————————————–
1 admin1-ib 172.23.1.254 admin1-ib quorum-manager
2 admin2-ib 172.23.1.255 admin2-ib quorum-manager
3 node001-ib 172.23.2.1 node001-ib quorum
4 node002-ib 172.23.2.2 node002-ib
….
3) we do some tunning here:
[root@admin1 gpfs]# mmchconfig verbsRdma=enable
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
And then defining the Fabric that need to be used. Important point is that here we put also */*/2 which means be in the same fabric as Storage side GPFS.
[root@admin1 gpfs]# mmchconfig verbsPorts=mlx4_0/1/2
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
[root@admin1 ~]# ibstat
CA ‘mlx4_0’
CA type: MT4099
Number of ports: 2
Firmware version: 2.35.5100
Hardware version: 1
Node GUID: 0x049fca0300d2c40a
System image GUID: 0x049fca0300d2c40d
Port 1:
State: Active
Physical state: LinkUp
Rate: 56
Base lid: 465
LMC: 0
SM lid: 465
Capability mask: 0x0251486a
Port GUID: 0x049fca0300d2c40b
Link layer: InfiniBand
Port 2:
State: Down
Physical state: Polling
Rate: 10
Base lid: 0
LMC: 0
SM lid: 0
Capability mask: 0x02514868
Port GUID: 0x049fca0300d2c40c
Link layer: InfiniBand
[root@admin1 gpfs]# mmchconfig socketMaxListenConnections=1024
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
[root@admin1 gpfs]# mmchconfig nistCompliance=off
mmchconfig: Command successfully completed
mmchconfig: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
4) starting the Cluster and checking if all is OK.
[root@admin1 gpfs]# mmstartup -a
[root@admin1 gpfs]# mmgetstate -a
We have to make sure that no firewall is on in any node otherwise it blocks the communication in GPFS.
Important point: If for any reason we need to redeploy any nodes like compute nodes from xCAT, we need to reload the GPFS configuration afterward. And we can do this from script or directly on the node after deployment.
# Restore the latest GPFS system files
echo “Restoring GPFS configuration files from a GPFS member server”
if [ $CLUSTER = “XXX” ]; then
scp ${PRIMARY_SERVER}:/var/mmfs/gen/mmsdrfs /var/mmfs/gen/mmsdrfs
scp ${PRIMARY_SERVER}:/var/mmfs/ccr/ccr.disks /var/mmfs/ccr/ccr.disks
scp ${PRIMARY_SERVER}:/var/mmfs/ccr/ccr.nodes /var/mmfs/ccr/ccr.nodes
scp ${PRIMARY_SERVER}:/var/mmfs/ssl/stage/* /var/mmfs/ssl/stage/
else
scp ${PRIMARY_SERVER}:/var/mmfs/ssl/stage/* /var/mmfs/ssl/stage/
/usr/lpp/mmfs/bin/mmsdrrestore -p ${PRIMARY_SERVER} -R /usr/bin/scp
if [ $? -ne 0 ];then
echo “ERROR: Restoring GPFS configuration failed!”
exit 1
fi
fi
So XXX is the cluster which has CCR type of configuration and else is the one which is not CCR and is based on Primary and Secondary kind of configuration. In our case which our compute GPFS cluster is based on Primary/Secondary kind of configuration the “else” clause is being used. First we need to copy the related keys from primary server and then restore the configuration with “mmsdrrestore”.
***************************************************************************
C. Multi cluster connection- Storage GPFS side and Compute GPFS side
From each cluster that we want to connect we must choose a node as an representor and run the commands between this 2 cluster. It doesn’t matter which cluster we choose since GPFS will run the commands in all of the members of that cluster in any case.
I choose nsd1 from Storage gpfs side and admin1 from compute gpfs side.
On admin1
=======================================================================
1) first we create the key pair
mmauth genkey new
2) shut down complete file-system
mmshutdown -a
3) mmauth update . -l AUTHONLY
4) scp /var/mmfs/ssl/id_rsa.pub nsd1:/tmp/id_rsa.pub
On nsd1
=======================================================
1) We need to add the public key of compute gpfs side.
mmauth add hrouhani.compute -k /tmp/id_rsa.pub
2) rm /tmp/id_rsa.pub
3) mmauth show
4) mmauth grant hrouhani.compute -f /dev/gpfs_scratch
5) mmauth show
On admin1
==========
1) scp nsd1:/var/mmfs/ssl/id_rsa.pub /tmp/id_rsa.pub
2) mmremotecluster add hrouhani.storage -n nsd1-ib,nsd2-ib,nsd3-ib,nsd4-ib,nsd5-ib,nsd6-ib -k /tmp/id_rsa.pub
3) mmremotecluster show
rm /tmp/id_rsa.pub
4) mmremotefs add /dev/gpfs_scratch -f /dev/gpfs_scratch -C hrouhani.storage -T /scratch -A no
5) mmremotefs show
6) mmstartup -a
mmmount gpfs_scratch
so basically the scratch directory which is our mount point in Storage GPFS side will be mounted here.
