I first shortly describe what is hadoop in a way which fully be understood be reader. Then I move on into proper hadoop cluster design and at the end I go through installation and configuration of hadoop cluster based on Hortonworks Data Platform (HDP) which is fully open-source and can be used for any enterprise organization free of cost.
What is Hadoop
Open source software framework for storage and large scale processing of data-sets on a cluster of commodity hardware. Here commodity means we do not need necessarily the good and high speed hardware, but cheap computation and storage also is good enough. The reason is based on the fact that hadoop has a scalable architecture that can distribute data-sets on all machines. Maybe one of the main advantage of hadoop is the reliability concept, so any hardware failure can be tolerated. So we can say the main idea behind hadoop is to move computation to data instead of moving data to computation.
A Hadoop cluster scales computation capacity, storage capacity and I/O bandwidth by simply adding more servers. Two components are the essential parts of HDP (or any hadoop cluster) which are Hadoop Distributed File System (HDFS) and YARN.
Description: Here my focus is mainly on new version of hadoop which is version 2.0 that provides several revolutionary features such as Yarn, HDFS federation and High Available NameNode which has tremendous advantage to previous hadoop version 1 in terms of efficiency and reliability.
HDFS is a Java-based file-system that provides scalable, reliable, fault-tolerant, cost efficient and high throughput storage for applications that have big data sets.
YARN is a resource manager that enable several workloads (data processing engines) to process data simultaneously or better say access the same data set. YARN came up since Hadoop version 2 and it changed the hadoop platform from Single Use System (Batch Apps (MapReduce)) to Multi Purpose Platform (Batch, Interactive(Tez), Streaming(Storm), Online(Hbase), In-Memory(Spark),…). I would say the main power of the YARN is allowing other applications (open-source or proprietary) to have access to Hadoop cluster and use the data set through HDFS.
YARN takes into account all of the available compute resources on each machine in the cluster. Based on the available resources, YARN negotiates resource requests from applications running in the cluster such as MapReduce. YARN then provides processing capacity to each application by allocating Containers. A Container is the basic unit of processing capacity in YARN, and is an encapsulation of resource elements such as memory and CPU.
In a Hadoop cluster, it is vital to balance the use of memory (RAM), processors (CPU cores) and disks so that processing is not constrained by any one of these cluster resources.
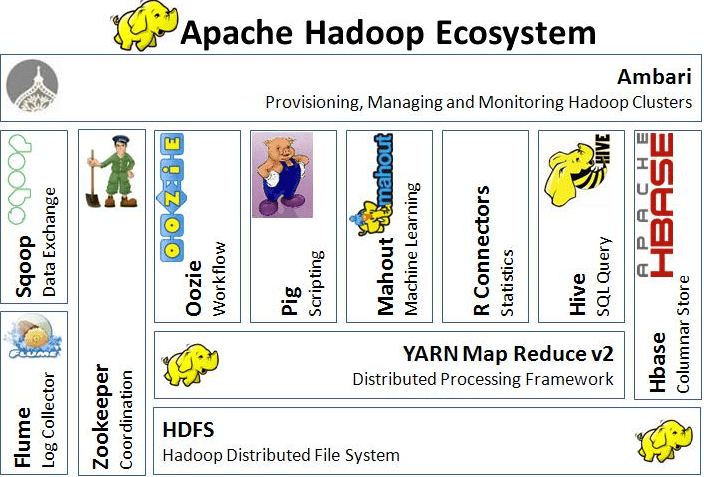
The HDFS and YARN layer are same among all hadoop distributions and what makes different is the upper layer which can be different tools. As can be seen in above figure, we have many different tools in hortonworks distribution which is more or less same in other hadoop distribution like cloudera, MapR and IBM.
Hadoop Cluster Design
In general we have 2 types of machines in hadoop cluster – Master or Slave. The terms comes from the fact that some of the services in Hadoop cluster have master/slave (server/client) architecture. And as a result the Master (server) services always is going to locate at Master node(s).
I would say the main design part of hadoop cluster is choosing the number of Master nodes beside their hardware specifications. And the number/spec of Master node(s) is dependent on what services we are going to run on the cluster, how many slave nodes they are going to serve and do we have a High-Availability concept in place like primary and secondary Namenode and Resource manager.
What really distinguish slave nodes from Master nodes, is the fact that if Slave node(s) is dying or dismantle for any reason, nothing should affect the cluster running tasks/jobs.
Since I want to install all services that HDP v2.4 is providing, I classify the Master node(s) and Slave nodes as follow:
-
Masters – Ambari server, HDFS NameNode, YARN ResourceManager, and HBase Master, Zookeeper server, Spark History server, Accumulo Master, Accumulo Monitor, Accumulo Tracer, Accumulo GC, SmartSense HST server, Kafka Broker, Atlas Metadata Server, Knox Gateway, Snamenode, History server, App Timeline server, Hive Metastore, WebHCat server, Hiverserver2, Oozie Server, Falcon Server, DRPC server, Nimbus, Storm UI server, Metrics collector, Accumulo Tserver
-
Slaves — DataNodes (HDFS client), NodeManagers (YARN client), and RegionServers (HBASE client), supervisor, Flume, MapReduce2 client, Tez client, Hcat client, Hive client, Pig client, Sqoop client, Oozie client, Zookeeper client, Falcon client, Accumulo client, Mahout client, Slider client, Spark client
In my case, since I have 5 nodes in total and planning to install all services, I would go with 2 Master nodes and 3 slave nodes (compute nodes).
Some important points:
-
Hbase needs the use of Zookeeper component in order to manage the cluster
-
For better performance and probably optimal data locality (reusing the data that it recently used) is better to have DataNodes, NodeManagers, and HBase RegionServers on same slave nodes. So I will hosts all of these services on all slave nodes.
File-system partitioning
Before we continue with HDP installation, we need to take into consideration several points regarding the partitioning. Same as before, I also separate these tasks into 2 categories:
Master-node (s): Root partition for OS and core programs + 2 times System Memory (RAM) for Swap. If you have at least 4 Drives I would suggest Raid 10, otherwise with 2 Drives Raid 1 would be OK.
Slave nodes: I divide into 3 parts: OS + Swap + Hadoop files
a. /root partition for OS and major programs (like HDFS client,….)
b. Swap same as master node : 2X RAM
c. Hadoop files and logs which HDFS file-system will come at top of the local Linux file-system. Based on Hortonworks the best local file-system choice is ext3 which makes it safest option. The ext4 might have potential data loss due to delayed writes features by using defaults option. The XFS also has data loss issue upon power failure. LVM also has latency issues and can be a bottleneck. We can divide this category into several partitions which should be mounted from drives as /grid/[0-n].
In my case I have a 4TB Disk in each Slave node (node02, node03, node04) which 3980GB is usable. I devote 100 GB to OS and related hadoop slave daemons. My RAM is 65 GB, so my swap size will be 130 GB. I go with 4 partitions of each 900 GB for Hadoop files (HDFS file-system).
d. Raid configuration is not necessary for Slave nodes as data on this nodes are stored on at least 3 different hosts (maybe targets). As a result the redundancy is built-in.
Installation & Configuration
I assume that the cluster is already deployed with 1 Master node (xCAT master node) and 4 other nodes based on Centos 7.2 which we will decide later the role of each of them. The 4 nodes are deployed through Diskfull provisioning as I explained in xCAT part in HPC thread. You can offcourse use any other deployment tools like OpenHPC or Forman/Puppet.
My plan is to install automatically the HDP (hadoop cluster) by using ambari tool. Ambari tool can be installed in any node even external node which is not part of the cluster. In my case I will install it on main xCAT master node.
What is Ambari
The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Ambari has a server/client architecture. So it means that ambari-server will install everything for us in different nodes (including of Master node) through ambari-client (ambari-agent) which needs to be installed in other nodes.
hadoop-master is the name of my xCAT master node which has been used for deploying other four nodes. Since I already defined the design before deploying the nodes, I gave them appropriate names which are:
- hadoop-master2.hpc.cluster
- node-01.hpc.cluster
- node-02.hpc.cluster
- node-03.hpc.cluster
So we start from our master node since the target is to install ambari server on this node and deploy hadoop cluster from this node by using ambari. We need to check or install several things beforehand and then continue by ambari server installation and hadoop deployment.
1. check if firefox & python already installed otherwise install it.
- [root@hadoop-master ~]# firefox -v
- Mozilla Firefox 38.3.0
- [root@hadoop-master ~]# python -V
- Python 2.7.5
2. change the File Descriptor to proper value. be defaults the values are very small as can be seen here
- [root@hadoop-master ~]# ulimit -Sn
- 1024
- [root@hadoop-master ~]# ulimit -Hn
- 4096
So I changed it to a suitable value as can be see here, however it is not permanent and will go to default value as we reboot the system.
- [root@hadoop-master ~]# ulimit -n 10000
Description: file descriptor, when you open a file, the operating system creates an entry to represent that file and store the information about that opened file. So if there are 100 files opened in your OS then there will be 100 entries in OS (somewhere in kernel). These entries are represented by integers like (…100, 101, 102….). This entry number is the file descriptor. So it is just an integer number that uniquely represents an opened file in operating system. If your process opens 10 files then your Process table will have 10 entries for file descriptors. Similarly when you open a network socket, it is also represented by an integer and it is called Socket Descriptor.
3. set password-less ssh between master node and other 4 nodes in case ambari use it. I already set Password-less SSH between xCAT master node and clients simply by copying the public key of master node to all other nodes: (example)
[root@hadoop-master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node-01
4. service user account: In general Hadoop services should be owned by specific users and not by root or application users. If you choose to install the HDP components using the RPMs, these users will automatically be set up. Each HDP service requires a service user account. The Ambari Install wizard creates new and preserves any existing service user accounts, and uses these accounts when configuring Hadoop services. Service user account creation applies to service user accounts on the local operating system and to LDAP/AD accounts.
5. time synchronization: for time synchronization I used chrony at first but later changed to traditional ntpd daemon since during hadoop installation I noticed that hadoop is referring to ntpd daemon and looking for it. Please read time synchronization thread if you have problem.
6. DNS configuration: all hosts (here Master node and compute nodes) must be able to do the forward and reverse DNS. In our case which we configured in xCAT, we have a DNS server in Master node and all compute nodes are referring to it. However in worst case it is also possible to modify /etc/hosts file in all nodes and write the name and IP add.
Explanation: Forward DNS lookup is using an Internet domain-name to find an IP address. Reverse DNS lookup is using an Internet IP address to find a domain name.
To test if all is fine do following kind of tests between nodes:
- [root@node-01 ~]# nslookup node-02
- Server: 10.0.0.254
- Address: 10.0.0.254#53
- Name: node-02.hpc.cluster
- Address: 10.0.0.2
- [root@node-01 ~]# nslookup 10.0.0.2
- Server: 10.0.0.254
- Address: 10.0.0.254#53
- 2.0.0.10.in-addr.arpa name = node-02.hpc.cluster.
Hadoop relies heavily on DNS, and as such performs many DNS lookups during normal operation. To reduce the load on your DNS infrastructure, it’s highly recommended to use the Name Service Caching Daemon (NSCD) on cluster nodes running Linux. This daemon will cache host, user, and group lookups and provide better resolution performance, and reduced load on DNS infrastructure.
7. Based on hortonworks recommendation, It is better to stop iptables temporary if we are not sure certain ports that we need are open. I keep the iptables service on (all ports accepted conf) as I will install all through ambari and as a result the nodes need to have Internet Access and as a result Master node should do NATing. I gave internet access through NAT from Master node by iptables configuration. Please read NAT with iptables thread if you have problem. In order to test the situation regarding the port I used following command:
- [root@hadoop-master ~]# nmap 10.0.0.1
- Starting Nmap 6.40 ( http://nmap.org ) at 2016-08-17 09:08 CEST
- Nmap scan report for node-01 (10.0.0.1)
- Host is up (0.00012s latency).
- Not shown: 999 closed ports
- PORT STATE SERVICE
- 22/tcp open ssh
- MAC Address: 50:46:5D:E8:B6:D8 (Asustek Computer)
- Nmap done: 1 IP address (1 host up) scanned in 0.14 seconds
Closed ports have no application listening on them, though they could open up at any time. So do not get confused with filtered ports.
8. Selinux must be disabled on all hosts as we did through xCAT Diskfull deployment
9. We need to make sure that PackageKit is disabled on all nodes. In my case it is active and enabled in Master node. So we can do following commands:
- [root@hadoop-master ~]# systemctl stop packagekit.service
- [root@hadoop-master ~]# systemctl disable packagekit.service
Explanation: RedHat provides PackageKit for viewing, managing, updating, installing and uninstalling packages compatible with your system. PackageKit consists of several graphical interfaces that can be opened from the GNOME panel menu, or from the Notification Area when PackageKit alerts you that updates are available. You can open the GUI with this command: gpk-update-viewer.
10. Make sure that umask of 0022 is in place on all nodes. We can check it simply by executing umask command. In my case all nodes are 0022. If it is not in your case, you can change it by following command:
echo umask 0022 >> /etc/profile
Explanation: UMASK (User Mask or User file creation MASK) sets the default permissions or base permissions granted when a new file or folder is created on a Linux machine. Most Linux distros set 022 as the default umask value. A umask value of 022 grants read, write, execute permissions of 755 for new files or folders. A umask value of 027 grants read, write, execute permissions of 750 for new files or folders.
Ambari & HDP support umask values of 022 (0022 is functionally equivalent), 027 (0027 is functionally equivalent). These values must be set on all hosts
11. at the moment I skip using Local Repository and the target is to install everything from Internet.
12. creating the appropriate repository for ambari in Master node (ambari server). Download ambari repositories (repo files).
wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
- [root@hadoop-master ~]# ls /etc/yum.repos.d/
ambari.repo CentOS-Debuginfo.repo CentOS-Sources.repo epel-testing.repo mysql-community.repo xCAT-dep.repo CentOS-Base.repo CentOS-fasttrack.repo CentOS-Vault.repo HDP.repo mysql-community-source.repo
CentOS-CR.repo CentOS-Media.repo epel.repo HDP-UTILS.repo xCAT-core.repo
We do not need to install manually the ambari repo in slave nodes (other nodes) as ambari-server during the deployment will do that.
- [root@hadoop-master ~]# cat /etc/yum.repos.d/HDP.repo
[HDP-2.4]
name=HDP-2.4
baseurl=http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0
path=/
enabled=1
- [root@hadoop-master ~]# cat /etc/yum.repos.d/HDP-UTILS.repo
[HDP-UTILS-1.1.0.20]
name=HDP-UTILS-1.1.0.20
baseurl=http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7
path=/
enabled=1
13. installing ambari-server
[root@hadoop-master ~]# yum install ambari-server
Beside ambari-server, it will install following 3 packages as well.
- postgresql
- postgresql-libs
- postgresql-server
14. setup the ambari server. Several important things need to be configured in this step as I explain later.
[root@hadoop-master ~]# ambari-server setupUsing python /usr/bin/pythonSetup ambari-serverChecking SELinux...SELinux status is 'disabled'Customize user account for ambari-server daemon [y/n] (n)?Adjusting ambari-server permissions and ownership...Checking firewall status...Redirecting to /bin/systemctl status iptables.serviceChecking JDK...[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8[2] Oracle JDK 1.7 + Java Cryptography Extension (JCE) Policy Files 7[3] Custom JDK==============================================================================Enter choice (1): 1To download the Oracle JDK and the Java Cryptography Extension (JCE) Policy Files you must accept the license terms found at http://www.oracle.com/technetwork/java/javase/terms/license/index.html and not accepting will cancel the Ambari Server setup and you must install the JDK and JCE files manually.Do you accept the Oracle Binary Code License Agreement [y/n] (y)?Downloading JDK from http://public-repo-1.hortonworks.com/ARTIFACTS/jdk-8u60-linux-x64.tar.gz to /var/lib/ambari-server/resources/jdk-8u60-linux-x64.tar.gzjdk-8u60-linux-x64.tar.gz... 100% (172.8 MB of 172.8 MB)Successfully downloaded JDK distribution to /var/lib/ambari-server/resources/jdk-8u60-linux-x64.tar.gzInstalling JDK to /usr/jdk64/Successfully installed JDK to /usr/jdk64/Downloading JCE Policy archive from http://public-repo-1.hortonworks.com/ARTIFACTS/jce_policy-8.zip to /var/lib/ambari-server/resources/jce_policy-8.zipSuccessfully downloaded JCE Policy archive to /var/lib/ambari-server/resources/jce_policy-8.zipInstalling JCE policy...Completing setup...Configuring database...Enter advanced database configuration [y/n] (n)?Configuring database...Default properties detected. Using built-in database.Configuring ambari database...Checking PostgreSQL...Running initdb: This may take upto a minute.Initializing database ... OKAbout to start PostgreSQLConfiguring local database...Connecting to local database...done.Configuring PostgreSQL...Restarting PostgreSQLExtracting system views.........ambari-admin-2.2.2.0.460.jarAdjusting ambari-server permissions and ownership...Ambari Server 'setup' completed successfully.
Basically following things happened during our setup.
-
the user account the Ambari server daemon will run as. Here I chose root and therefore proceed with default option.
- Configure the Database for Ambari. I use the default, embedded PostgreSQL database for Ambari and as a result do not enter Advanced Database Configuration. The default PostgreSQL database name is ambari. The default user name and password are ambari/bigdata
-
Install appropriate JDK. Since my plan is to install HDP version 2.4, I will choose Oracle JDK 1.8
- [root@hadoop-master ~]# ambari-server status
- Using python /usr/bin/python
- Ambari-server status
- Ambari Server running
- Found Ambari Server PID: 11131 at: /var/run/ambari-server/ambari-server.pid
15. Starting with using ambari for deployment and configuration. By now our ambari server has been installed and we can use it through web by following: http://10.0.0.254:8080 or simply use the name of the Master node. Username/Password is admin/admin.
And then we choose “launch install wizard”.
We give a name to the cluster: BigData
and at the next page we need to select the stack. I leave the default HDP 2.4, and then expand the Advanced Repository Options. In the repository option, I only click (check) the Redhat 7 as my Master node has access to the internet. Without Internet I need to create local mirror of the Stack repository that is accessible by all hosts and use that URLs here.
16. Install Options: In order to build up the cluster, the install wizard prompts you for general information about how you want to set it up. You need to supply the FQDN of each of your hosts. The wizard also needs to access the private key file you created in Set up password-less SSH. Using the host names and key file information, the wizard can locate, access, and interact securely with all hosts in the cluster.
So I entered:
- hadoop-master.hpc.cluster
- hadoop-master2.hpc.cluster
- node-01.hpc.cluster
- node-02.hpc.cluster
- node-03.hpc.cluster
then for the private key, we need to refer to the: /root/.ssh/id_rsa in our case. Click on the browser to show hidden files that you can see .ssh directory.
If you want to let Ambari automatically install the Ambari Agent on all your hosts using SSH, select Provide your SSH Private Key and either use the Choose File button in the Host Registration Information section to find the private key file that matches the public key you installed earlier on all your hosts or cut and paste the key into the text box manually.
Several important points that needs to be done beforehand:
a. since we put the Master node also in the list that ambari agent being installed, we need to put the Master public key also into authorized_keys file of Master node, that ambari server be able to do ssh to itself,
[root@hadoop-master ~]# cat id_rsa.pub >> authorized_keys
b. We need to make sure that compute nodes have Internet access. So I started again iptables service in Master node. That it can download the ambari.repo file through internet. Keep in mind that even we can install ambari-agent manually if we don’t have Internet access on nodes.
17. choose services:
Based on the Stack chosen during Select Stack, you are presented with the choice of Services to install into the cluster. HDP Stack comprises many services. You may choose to install any other available services now, or to add services later. The install wizard selects all available services for installation by default. I have chosen to install all services.
Ambari does not install Hue, or HDP Search (Solr). After adding some services, you may need to perform additional tasks.
18. design for distribution of services: I chose as follow the distribution of services:
- Hadoop-master:
- NameNode, ResourceManager, Hbase Master, Hive metastore, WebHCat Server, Hiverserver2, Oozie Server, Zookeeper server, Storm UI server, Spark History server, Grafana, Kafka Broker, Atlas Metadata server, Knox Gateway,
- Hadoop-master2:
- SnameNode, History Server, App Timeline, Zookeeper server, Falcon server, DRPC server, Nimbus, Accumulo Master, Acumulo Monitor, Acuumulo Tracer, SmartSense HST server, Accumulo GC, Metrics collector
- Slave nodes: Node-0[1-3] :
- DataNode, NodeManager, RegionServer, Supervisor, Flume, Accumulo Tserver, Client
19. Customize Services:
Important: If you are planning to install Hive, Hcatalog or Oozie, we need to install an appropriate database which store metadata information (metastore database). Beside we need the hostname, database name, username, and password for the metastore instance. There is a option to install a new database or use an existing database (if exists). Ambari by default choose a database type that can be changed if ever needed. Usually we have following database types to configure:
- Postgres (PostgreSQL)
- MySQL
- Oracle
- SQL Server
